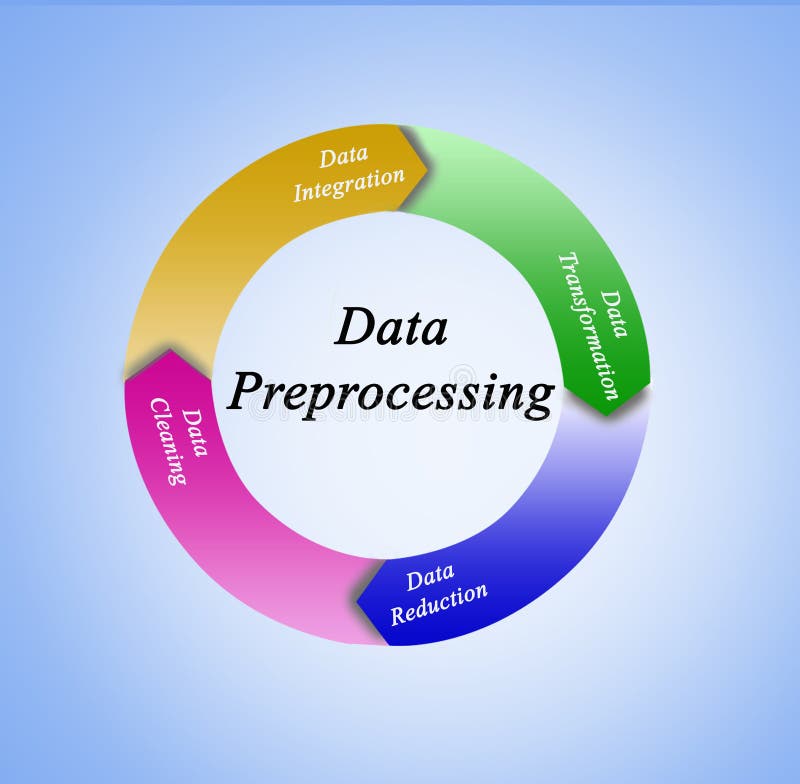
In the vast and intricate world of data analysis, one critical concept stands out: outlier detection. Outliers are data points that deviate significantly from the rest of the dataset. They may represent errors, anomalies, or rare events that carry valuable insights. Understanding and addressing outliers is crucial for accurate and reliable data analysis.
What is Outlier Detection?
Outlier detection refers to the process of identifying and handling data points that differ markedly from the majority of a dataset. These outliers can arise from measurement errors, data corruption, or genuine anomalies. Detecting them is vital because they can skew results, obscure trends, and affect the performance of machine learning models.
Types of Outliers
- Univariate Outliers: These outliers are found by analyzing a single variable. For example, a temperature reading of 1000°F in a weather dataset would be an obvious univariate outlier.
- Multivariate Outliers: These are identified by examining relationships among multiple variables. For instance, a combination of age and income that doesn’t align with typical patterns may indicate a multivariate outlier.
- Contextual Outliers: These depend on the context of the data. For instance, a high temperature may be normal in summer but an outlier in winter.
- Collective Outliers: A group of data points that deviate together, such as a sudden spike in website traffic during a cyberattack.
Methods of Outlier Detection
- Statistical Methods:
- Z-Score: Measures how far a data point is from the mean in terms of standard deviations.
- Interquartile Range (IQR): Detects outliers based on the spread of the middle 50% of the data.
- Machine Learning Techniques:
- K-Means Clustering: Identifies data points far from any cluster center.
- Isolation Forest: Detects anomalies by isolating observations.
- DBSCAN: A clustering algorithm that flags data points in low-density regions.
- Visualization Techniques:
- Boxplots: Highlight potential outliers visually.
- Scatter Plots: Reveal relationships and anomalies in multivariate data.
Applications of Outlier Detection
- Fraud Detection: In finance, outlier detection helps uncover fraudulent transactions or activities.
- Healthcare: Identifying abnormal patient vitals or test results.
- Cybersecurity: Detecting unusual patterns in network traffic to flag potential threats.
- Manufacturing: Monitoring sensor data to identify equipment malfunctions.
Challenges in Outlier Detection
- Imbalanced Data: Outliers are often rare, making them hard to identify.
- Dynamic Data: Evolving datasets may render static detection methods ineffective.
- Subjectivity: Determining whether a data point is an outlier often depends on the context.
Conclusion
Outlier detection is a cornerstone of robust data analysis and machine learning. By identifying and addressing these anomalies, organizations can ensure the integrity of their insights, improve decision-making, and detect critical events. As datasets grow in size and complexity, the importance of advanced outlier detection techniques continues to rise, making it an essential skill for data scientists and analysts alike.