In the world of data science and machine learning, the quality of your output is only as good as the quality of your input. This is where data preprocessing comes into play. Data preprocessing is a crucial step in the data pipeline that ensures raw data is cleaned, transformed, and made ready for analysis or model training. Without it, even the most sophisticated algorithms might fail to deliver accurate results.
What is Data Preprocessing?
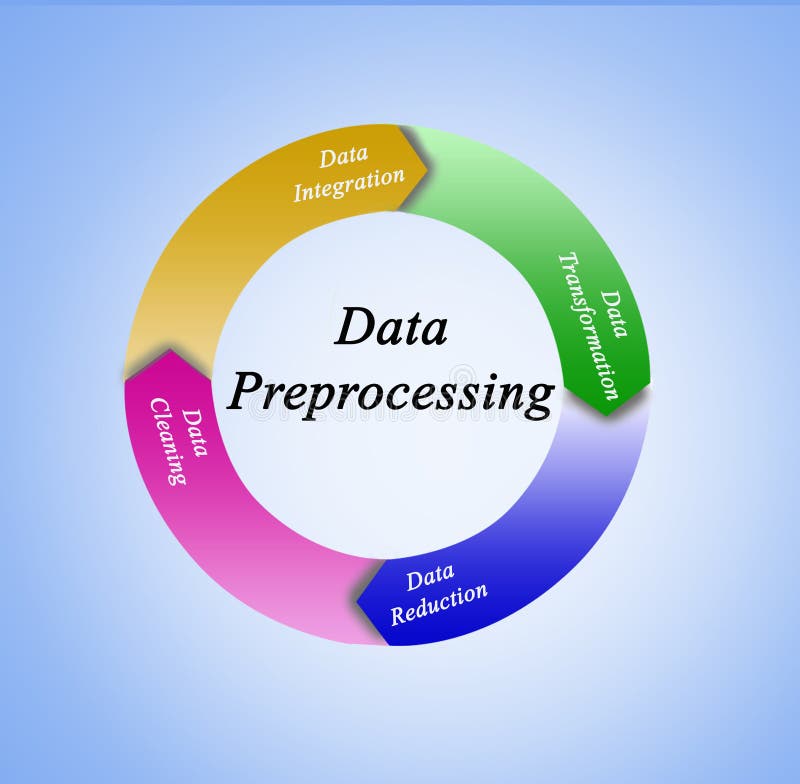
Data preprocessing is the process of preparing raw data to make it suitable for a machine learning model. Raw data often comes with inconsistencies, missing values, noise, and irrelevant features. Preprocessing eliminates these issues, transforming raw data into a clean and structured format.
Why is Data Preprocessing Important?
- Improved Model Performance: Well-preprocessed data leads to better performance of machine learning models.
- Reduction of Noise: Removes irrelevant or redundant information that could mislead the algorithm.
- Better Handling of Missing Data: Properly addressing missing values prevents inaccuracies in model predictions.
- Feature Scaling: Ensures numerical stability and accelerates the convergence of algorithms.
- Enhanced Interpretability: Cleaned and normalized data is easier to analyze and interpret.
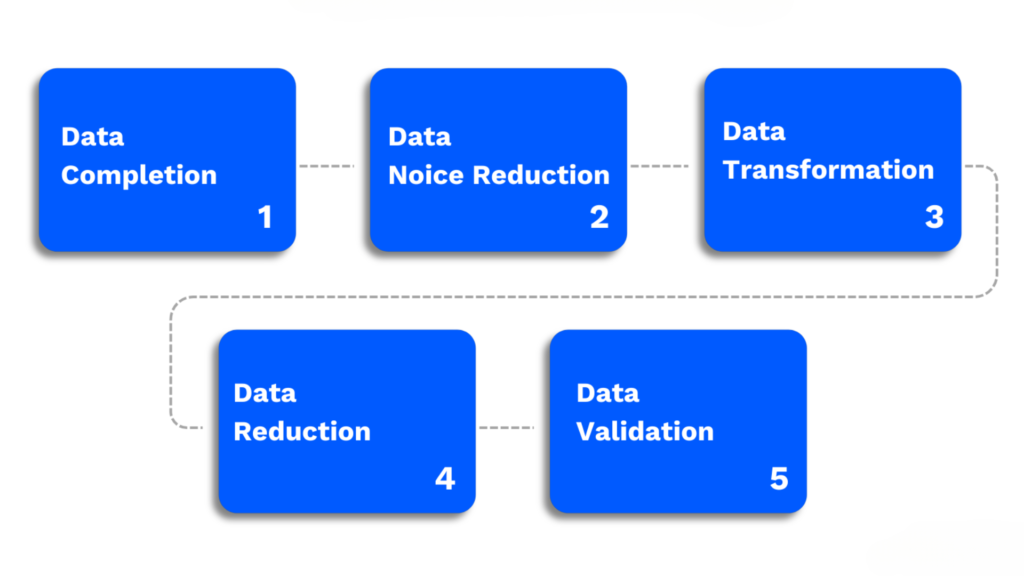
Key Steps in Data Preprocessing
1. Data Completion
Definition:
Data completion refers to the process of handling missing data to ensure that the dataset is complete and usable. Missing values in a dataset can occur due to data entry errors, system failures, or incomplete responses in surveys.
Why It’s Important:
Missing data can lead to biased analysis or incorrect predictions. Most machine learning algorithms cannot handle missing values, so addressing them is critical.
Common Techniques:
- Imputation:
- Replace missing values with statistical metrics:
- Mean (for numerical data): e.g., Replace missing heights with the average height.
- Median (for skewed data): e.g., Replace missing income values with the median income.
- Mode (for categorical data): e.g., Replace missing gender entries with the most frequent value.
- Use predictive modeling (e.g., regression) to estimate missing values based on other features.
- Replace missing values with statistical metrics:
- Deletion:
- Remove rows or columns with excessive missing data if they contribute minimal value to the analysis.
- Using Default Values:
- Assign default values, such as “Unknown” or “0,” to missing data in specific cases.
Example:
Imagine a dataset containing customer information where the Age column has some missing values. If 10% of the rows have missing Age, we might replace those values with the mean age of the customers.
2. Data Noise Reduction
Definition:
Noise in data refers to irrelevant, erroneous, or inconsistent information that can mislead machine learning models. Noise can arise from measurement errors, data entry mistakes, or random anomalies.
Why It’s Important:
If noisy data is not addressed, it can distort patterns, reduce model accuracy, and increase overfitting.
Common Techniques:
- Outlier Detection:
- Use statistical methods like the Z-score or the interquartile range (IQR) to identify and remove or correct outliers.
- Example: If a person’s income is listed as $1 billion in a dataset of average incomes, it can be flagged as an outlier.
- Smoothing:
- Apply algorithms like moving averages or median filtering to smooth noisy signals or data points.
- Binning:
- Group continuous data into intervals or “bins” to reduce noise, especially in large datasets.
- Clustering:
- Use clustering algorithms (e.g., k-means) to identify and isolate noisy data points.
- Feature Engineering:
- Eliminate noisy variables by transforming them into more meaningful ones.
Example:
In a dataset containing stock prices, random spikes in prices due to data logging errors can be smoothed using a rolling average.
3. Data Transformation
Definition:
Data transformation involves converting raw data into a format that is compatible with machine learning algorithms. This step ensures uniformity and prepares the data for analysis.
Why It’s Important:
Data in its raw form may not be in the correct format (e.g., categorical data) or scale (e.g., features with different units) for model training.
Common Techniques:
- Normalization:
- Scale numerical data to a fixed range, such as [0,1].
- Example: Transform weights (in kilograms) ranging from 30 to 150 into a 0 to 1 range.
- Standardization:
- Scale data to have a mean of 0 and a standard deviation of 1.
- Example: Transform test scores to standard scores (z-scores).
- One-Hot Encoding:
- Convert categorical variables into binary vectors.
- Example: Convert
City= {London, Paris, New York} into separate columns (London: [1, 0, 0], Paris: [0, 1, 0], New York: [0, 0, 1]).
- Log Transformation:
- Apply log transformation to skewed data to make it more normally distributed.
- Example: Apply
log(x)to sales data with extreme highs and lows.
Example:
In a dataset with features like Height (cm) and Weight (kg), normalization ensures both are on the same scale to avoid one feature dominating the analysis.
4. Data Reduction
Definition:
Data reduction focuses on simplifying the dataset without losing valuable information. It aims to reduce computational complexity and storage requirements while improving the model’s interpretability.
Why It’s Important:
High-dimensional data (data with many features) can lead to the curse of dimensionality, where models struggle to generalize.
Common Techniques:
- Feature Selection:
- Retain only the most relevant features using statistical tests (e.g., chi-square test) or algorithms (e.g., Recursive Feature Elimination, Lasso Regression).
- Example: Retain
AgeandIncomefrom a dataset with 20 features if they are most correlated with the target variable.
- Dimensionality Reduction:
- Use algorithms like PCA (Principal Component Analysis) to reduce the number of features while preserving variance.
- Example: Combine multiple correlated features like
HeightandArm Lengthinto a single principal component.
- Sampling:
- Reduce the size of the dataset by selecting a representative subset.
- Example: Randomly select 10,000 rows from a dataset of 1 million rows for faster processing.
5. Data Validation
Definition:
Data validation ensures the processed data is accurate, consistent, and ready for analysis or training.
Why It’s Important:
Validation helps to catch errors introduced during preprocessing and ensures the data aligns with the expected format and structure.
Common Techniques:
- Check for Duplicates:
- Ensure no duplicate rows or entries exist.
- Verify Data Consistency:
- Check if all data points follow logical rules (e.g.,
Start Date<End Date).
- Check if all data points follow logical rules (e.g.,
- Cross-validation:
- Divide data into training and testing sets multiple times to ensure robustness.
- Data Type Validation:
- Confirm that all values match their expected types (e.g., numerical, categorical).
Example:
In a dataset for customer transactions, validation ensures that all Transaction Dates are within the business’s operational period and not in the future.
Tools and Libraries for Data Preprocessing
Several tools and libraries simplify preprocessing:
- Python Libraries:
Pandas: For data manipulation and cleaning.NumPy: For numerical operations.Scikit-learn: For feature scaling and encoding.
- R: Provides robust preprocessing packages like
dplyrandcaret. - Data Integration Tools: Apache NiFi, Talend.
Best Practices for Data Preprocessing
- Understand the Data: Perform exploratory data analysis (EDA) to gain insights into the dataset.
- Document Changes: Keep track of all preprocessing steps for reproducibility.
- Automate Where Possible: Use pipelines or scripts to automate repetitive tasks.
- Validate After Each Step: Regularly check the impact of preprocessing on data integrity.
Final Thoughts
Data preprocessing is not just a preliminary step; it is the backbone of any successful data-driven project. Skipping or inadequately performing preprocessing can lead to biased models, incorrect conclusions, and wasted resources. By investing time and effort in this critical phase, you pave the way for accurate predictions, actionable insights, and robust machine learning systems.
Preprocessed data isn’t just clean data—it’s smarter data. And in the world of machine learning, smarter data leads to smarter decisions.
