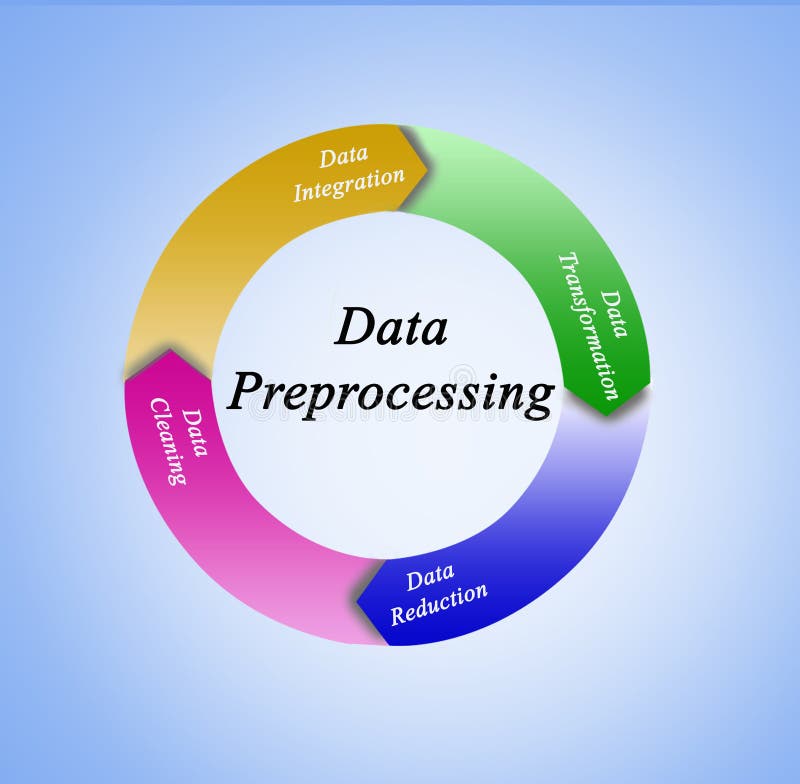
Classification is a supervised learning technique in machine learning where the goal is to categorize data into predefined labels or classes. It involves training a model on labeled data to predict the class or category of new, unseen data points.
Key Features of Classification
- Supervised Learning: Requires a labeled dataset for training.
- Discrete Output: Predicts categorical or binary outcomes, such as “Spam/Not Spam” or “Disease/No Disease.”
- Evaluation Metrics: Common metrics include accuracy, precision, recall, F1-score, and area under the ROC curve (AUC-ROC).
Types of Classification
- Binary Classification: Two classes (e.g., Yes/No, True/False).
- Example: Predicting whether an email is spam or not.
- Multi-Class Classification: More than two classes.
- Example: Classifying an image as a cat, dog, or bird.
- Multi-Label Classification: Assigns multiple labels to a single instance.
- Example: Tagging a photo with multiple labels like “beach,” “sunset,” and “vacation.”
Common Algorithms for Classification
- Logistic Regression
- Best for binary classification.
- Example: Predicting customer churn.
- Decision Trees
- Visualizes decisions and their possible outcomes.
- Example: Loan approval systems.
- Random Forest
- Ensemble method using multiple decision trees.
- Example: Diagnosing diseases based on symptoms.
- Support Vector Machines (SVM)
- Finds the optimal hyperplane for separating classes.
- Example: Image recognition.
- K-Nearest Neighbors (KNN)
- Classifies based on the majority vote of neighbors.
- Example: Recommending products based on user preferences.
- Naive Bayes
- Probabilistic classifier based on Bayes’ theorem.
- Example: Sentiment analysis.
- Neural Networks
- Handles complex data relationships and patterns.
- Example: Facial recognition systems.
Steps in Classification
- Data Preprocessing
- Clean and prepare the dataset (e.g., handle missing values, scale features).
- Splitting Data
- Divide the dataset into training and testing subsets.
- Feature Selection
- Identify the most relevant features to improve model performance.
- Model Training
- Train the classifier on the training data.
- Model Evaluation
- Use the testing data to assess model performance.
- Hyperparameter Tuning
- Optimize parameters to improve accuracy.
Applications of Classification
- Healthcare
- Predicting diseases based on medical history and symptoms.
- Finance
- Fraud detection in credit card transactions.
- E-commerce
- Recommending products based on user preferences.
- Email Filtering
- Classifying emails as spam or not spam.
- Social Media
- Identifying fake accounts or inappropriate content.
Evaluation Metrics for Classification
- Confusion Matrix: Summarizes prediction results.
- True Positive (TP), True Negative (TN), False Positive (FP), False Negative (FN).
- Accuracy:Accuracy=TP + TNTotal Predictions\text{Accuracy} = \frac{\text{TP + TN}}{\text{Total Predictions}}Accuracy=Total PredictionsTP + TN
- Precision:Precision=TPTP + FP\text{Precision} = \frac{\text{TP}}{\text{TP + FP}}Precision=TP + FPTP
- Recall:Recall=TPTP + FN\text{Recall} = \frac{\text{TP}}{\text{TP + FN}}Recall=TP + FNTP
- F1 Score:
Harmonic mean of precision and recall.F1 Score=2×Precision×RecallPrecision + Recall\text{F1 Score} = 2 \times \frac{\text{Precision} \times \text{Recall}}{\text{Precision + Recall}}F1 Score=2×Precision + RecallPrecision×Recall - ROC-AUC: Evaluates the trade-off between sensitivity and specificity.
Conclusion
Classification is a cornerstone of machine learning, offering solutions to a wide range of real-world problems. By choosing the right algorithm and optimizing model performance, businesses and researchers can achieve significant insights and predictions that drive innovation and decision-making.